Topic 12 Accessing online data sources
This section introduces some examples of R packages that allow you to access large secondary datasets. They are often a good way to understand wider trends, and thereby provide a high-level justification for doing research into a specific question. However, they can also be data sources for research projects in their own right.
12.1 World Bank data
The World Bank offers a rich dataset with a particular focus on indicators relevant for the study of poverty, inequality and global development (in fact, much of gapminder is based on World Bank data). You can explore their data online on data.worldbank.com, or access it directly from R using the wbstats package.
Here, I will explore the question whether life expectancy and literacy have increased in line with GDP in the BRICS countries (Brasil, Russia, India, China and South Africa, a group that has often been seen as representing emerging economies).
#Download current list of indicators
new_wb_cache <- wb_cache()
#Search for indicators - you can best do this on data.worldbank.com
#and find the IndicatorID in the URL. The wbsearch() function also works
#but often returns too many hits.
#GDP per capita, purchasing power adjusted
#(to remove effect of exchange rates)
wb_search("gdp.*capita.*PPP", cache = new_wb_cache)## # A tibble: 4 x 3
## indicator_id indicator indicator_desc
## <chr> <chr> <chr>
## 1 6.0.GDPpc_cons… GDP per capita, PPP (co… GDP per capita based on purchasing p…
## 2 NY.GDP.PCAP.PP… GDP per capita, PPP (cu… This indicator provides per capita v…
## 3 NY.GDP.PCAP.PP… GDP per capita, PPP (co… GDP per capita based on purchasing p…
## 4 NY.GDP.PCAP.PP… GDP per capita, PPP ann… Annual percentage growth rate of GDP…Once we know the names of the indicators, we can download them.
#Note: to get the country names, you can download all countries once
#and then check the names
#wb_dat <- wb(indicator = c("NY.GDP.PCAP.PP.KD", "SI.POV.GINI"), country = "all")
#wb_dat %>% count(iso2c, country) %>% view()
wb_dat <- wb_data(indicator = c("NY.GDP.PCAP.PP.KD", "SP.DYN.LE00.IN", "SE.TER.ENRR"),
country = c("IN", "BR", "CN", "ZA", "RU"), return_wide = FALSE)Now we have the data in a “long” format - with one combination of countries, indicators and years per row. That is a good layout for plotting, for other analyses you would need to reshape the data into a wide format where each indicator is in its own variable - look for the spread() function if you need that.
A simple way of comparing the data is plotting the indicators side-by-side. One interesting take-away is that Brazil massively improved life expectancy and expanded education, even though GDP growth was rather modest, while South Africa stagnated in comparison.
#Our GDP series only starts in 1990 - so it does not make sense
#to consider earlier life expectancy
wb_datF <- wb_dat %>% filter(as.numeric(date)>=1990)
ggplot(wb_datF, aes(x=as.numeric(date), y=value, col=country)) +
geom_point() + geom_line() +
facet_wrap(.~indicator, scales = "free", labeller = labeller(indicator = label_wrap_gen(25))) +
#scales = "free" means that each indicator has its own y-axis,
#the labeller() function is needed for line breaks in the facet titles
labs(title = "Uneven progress in BRICS countries", subtitle = "World Bank data",
x = "Year", y="", col = "Country")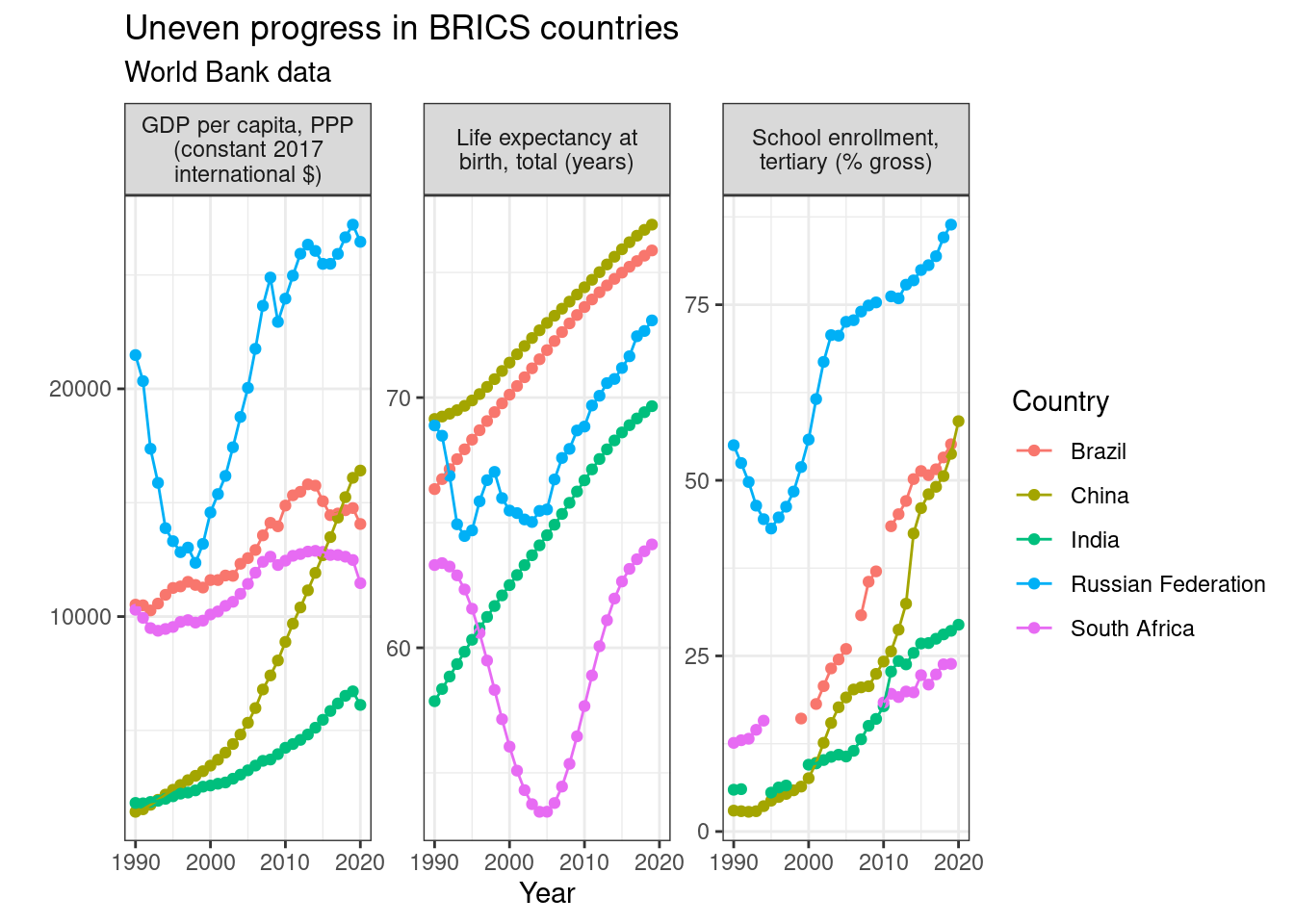
Figure 12.1: Example plot from World Bank data
You can find a similar but slightly more detailed example for how to use the package here and very clear instructions in the the full README file of the package.
12.2 Wikidata
Wikidata is where most data from Wikipedia and much else lives. So if there are Wikipedia articles on the topic you are interested in, you can likely find underlying data on Wikidata. For example, this might be used to quickly extract data on the gender of heads of government of many countries.
Wikidata is based on data items that are connected by multiple relationships. So there would be an item for Germany, an item for Angela Merkel and a relationship for is the head of government of. Similarly, there is an item for country and a relationship for is an instance of that connects it to Germany. SPARQL queries are used to get the data - this article explains the logic quite well, but unless you want to spend a couple more weeks learning how to code, you can just take examples from Wikidata and adjust them as needed. For adjusting them, the online Wikidata Query Service works well, as it allows you to run the query again and again, until you get the data you need.
I got curious about what share of the world’s population lives in countries with a female head of government, and how that varies by region. For that, I used the following code. (gt is a package to make nice tables easily.) Note that a key step is missing: I did not clean the data. It contains some duplicates, for instance because countries that span two continents are included twice in the Wikidata output. Data cleaning is a crucial part of analysing online data, but not the focus of this chapter.
pacman::p_load(WikidataQueryServiceR, gt)
headsOfGov <- query_wikidata('
SELECT ?country ?head ?gender ?countryLabel ?headLabel ?genderLabel ?continentLabel ?governmentLabel ?population
WHERE
{
?country wdt:P31 wd:Q6256 .
?country wdt:P6 ?head .
?head wdt:P21 ?gender .
?country wdt:P30 ?continent .
?country wdt:P1082 ?population .
SERVICE wikibase:label { bd:serviceParam wikibase:language "en" }
}
ORDER BY ?countryLabel
')
regional <- headsOfGov %>% group_by(continentLabel, genderLabel) %>% summarise(pop = sum(population), n = n()) %>% ungroup()
world <- data.frame(continentLabel = "World",
headsOfGov %>% group_by(genderLabel) %>%
summarise(pop=sum(population), n=n()),
stringsAsFactors = FALSE)
world %>% mutate(ShareOfCountries = n/sum(n)*100, ShareOfPopulation = pop/sum(pop)*100) %>% filter(genderLabel == "female") %>% select(ShareOfCountries, ShareOfPopulation) %>% round(1) %>% gt::gt() %>% gt::tab_header(title=gt::md("**Women rule**"), subtitle = "*Percent*")
regionalAndWorld <- rbind(regional, world)| Women rule | |
|---|---|
| *Percent* | |
| ShareOfCountries | ShareOfPopulation |
| 9.8 | 4.5 |
ggplot(regionalAndWorld, aes(x=continentLabel, y=pop, fill=genderLabel)) + geom_col(position="fill") +
#Turns chart into bars rather than columns
coord_flip() +
#Show percentages rather than fractions on y-axis (now shown as x-axis)
scale_y_continuous(labels=scales::percent) +
labs(title="Only a small fraction of the world's population is ruled by women", subtitle="Source: WikiData, February 2020", x="", y="Share of population", fill="Head of government")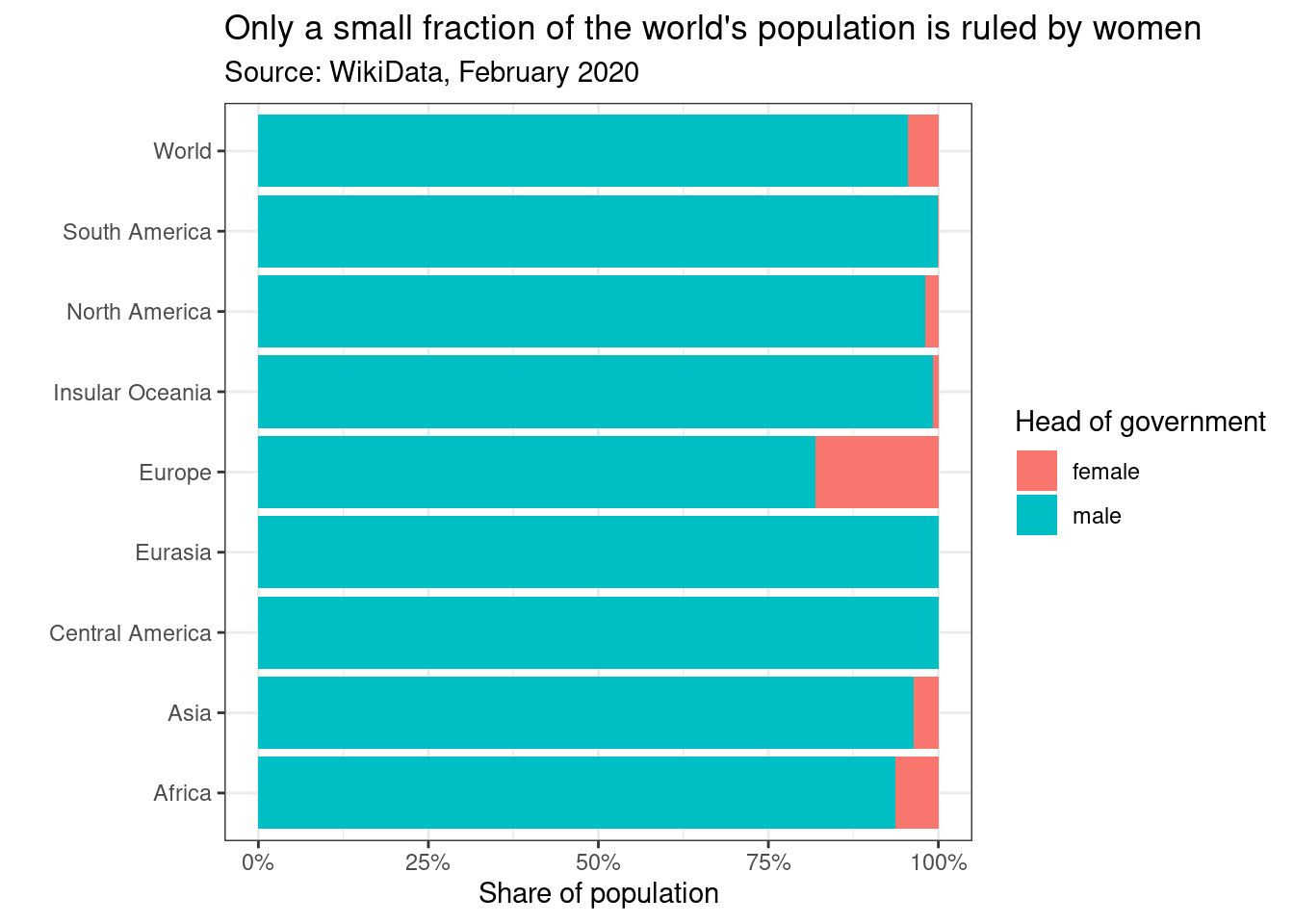
Figure 12.2: Example plot from Wikidata
12.3 Other data sources
Beyond the examples here, there are many other datasets to access. You might want to check out some of the following:
- The awesomedata collection has a huge range of links to datasets across all kinds of domains - from Museums to prostate cancer. Worth exploring.
- The extensive list of political datasets compiled by Erik Gahner, with lots of current and historical data on anything from terrorism to government revenues and gender in politics. At the bottom, it also has a list of links to other lists of datasets.
- Eurostat offers a lot of statistics on all countries in Europe. In R, it can be accesses with the
eurostatpackage; there is a good cheatsheet to help you get started - The webpage asdfree.com, with (sparse) instructions of how to access a wide range of online data sources, from very focused surveys such as the US National Longitudinal Study of Adolescent to Adult Health to international and very widely used datasets such as the World Values Survey.
- You can also use R to scrape data from pretty much any public webpage. This tutorial shows how to get data from IMDB, for instance.
- Finally, the
essurveypackage is the easiest way to get data from the European Social Survey into R. There is a good example for how to use it here